OpenMP Internals Part 2: Compilers: How Do They Work?
I am not a compiler expert. But, as we saw last time, if we’re going to learn how OpenMP outlining actually happens, then we’re going to need to crack open the bonnet (or “hood” for any yanks reading this) and see how a compiler actually works. I’ve done my best to ensure this post is relatively well researched, but this is an area in which I have no formal education. This is just one physicist’s view, and putting it together has been as much of a learning exercise for me as it has been anything else. As with all things, I welcome any corrections from more knowledgeable people.
So with that disclaimer out of the way, let’s talk about compilers. Specifically, I’m going to talk about GCC. I’d actually tossed-up whether or not to switch focus to LLVM for this post since is actually much better documented than GCC (and thus easier to write about), but GCC is far more commonly used in scientific computing, so presents a more common use-case (for me). I’m going to stick with GCC for now, but reserve the right to change focus to LLVM later in this series if GCC turns out to be too much of a hassle to research.
First, I’m going to give a high-level overview of the stages of the compilation process and how we get from source code to executable, then we’ll look at how to inspect the results after each stage, and finally see how OpenMP fits into the bigger picture. Let’s begin.
Table of Contents
The stages of a compiler
So what is a compiler anyway? At the highest possible level, a compiler is a program which translates a program between different languages. In most cases, you’ll probably use a compiler to translate from a high-level programming language like C or Fortran into executable machine code (a binary file), but there are also compilers which translate between high-level languages without producing any executable code (such as the myriad Fortran to C compilers). This latter category is qualitatively different to compilers which produce executable files, and are often referred to as transpilers or source-to-source compilers to emphasise the distinction. Transpilers are an interesting topic in their own right, but this post will focus on compilers which eventually produce machine code 1.
It’s easy to think of a compiler as a single, monolithic entity because, well, that’s the way most of us use them:
you type a single command like gcc or clang++ and it turns source-code into binaries with no further input
required. A cartoon view of this process might be:
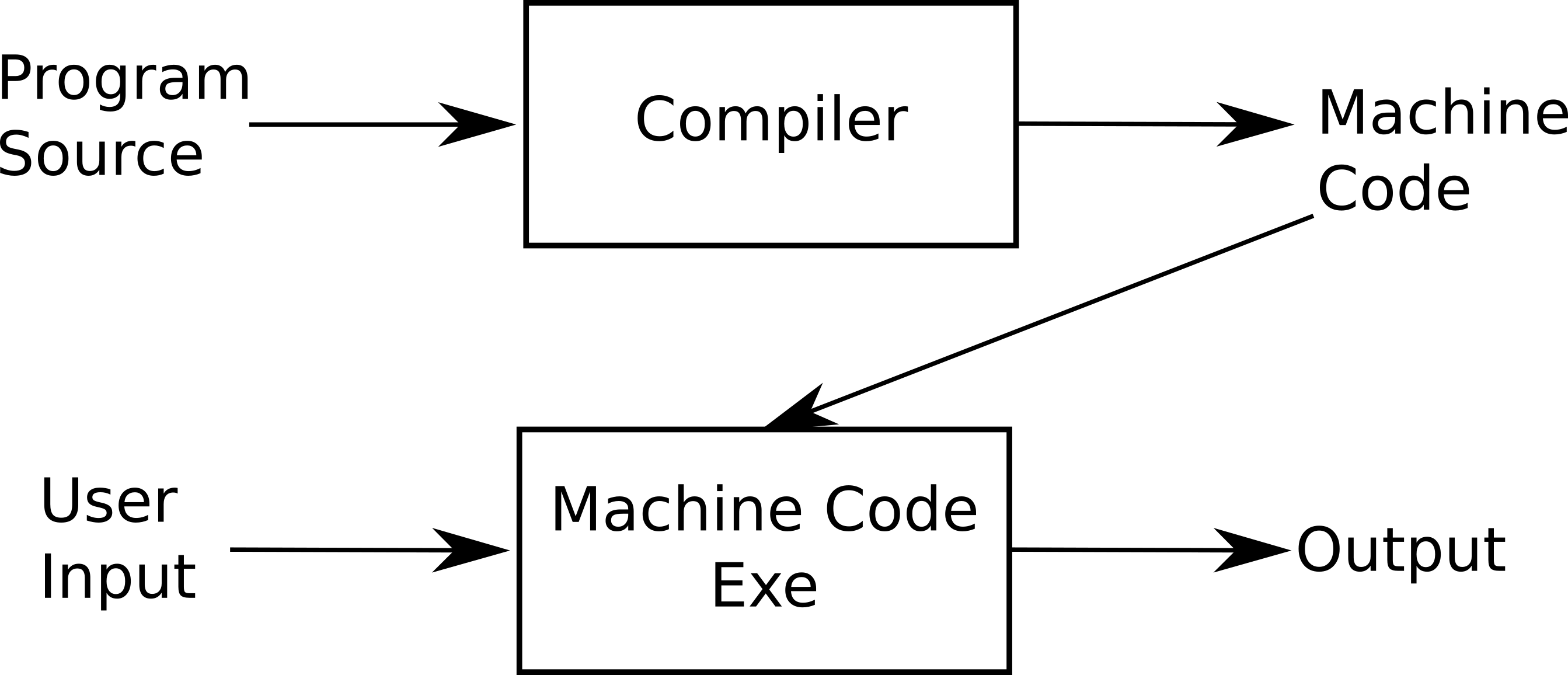
As you might expect, that first box in the diagram above is doing a lot of heavy lifting. To get a better view, we need to consider the interrelated requirements that we might impose on a compiler:
-
Understanding the source code - before we can turn the high-level source code into machine instructions, we first need to parse it and check that its valid, and then turn it into some representation which captures the idea of what the program is trying to do while being easier for the compiler to manipulate.
These two steps are called parsing and lexical analysis (or lexing), respectively, and are usually grouped together and referred to as the front-end. The parser and lexer necessarily depend on the formal specification of the original source language, and cannot be fully re-used between languages. Consequently, it is necessary to write a new parser and lexer for each new programming language to be supported. The front-end is also where syntax errors (like good old missing semicolons) are detected, and macro expansion occurs.
-
Optimisation - it’s pretty hard to write optimal code by hand, and highly-optimised code tends to be difficult to read and maintain, so it would be nice if the compiler could do some translations to make our code more effective. It’s already doing a bunch of translations anyway, so you might as well add one or more optimisation stages while we’re at it. This stage (part of the humorously oxymoronic middle-end stage) is highly nontrivial, and is where a lot of the engineering effort in compiler development ends up going. For reasons we’ll see in a moment, optimisations are split out into their own phase and are typically done on the compiler’s so-called intermediate representation (IR).
-
Finally, we need to translate the (possibly optimised) intermediate representation into the target language, usually the machine language for our target computer architecture. This stage is referred to as the compiler’s back-end. Each architecture will have its own machine language with different features and limitations, so we need a different back-end for each target architecture: one for x86, one for Arm, one NVIDIA GPU offloading, and so on.
Here’s a still-oversimplified-but-good-enough-for-our-purposes view of this three stage process:
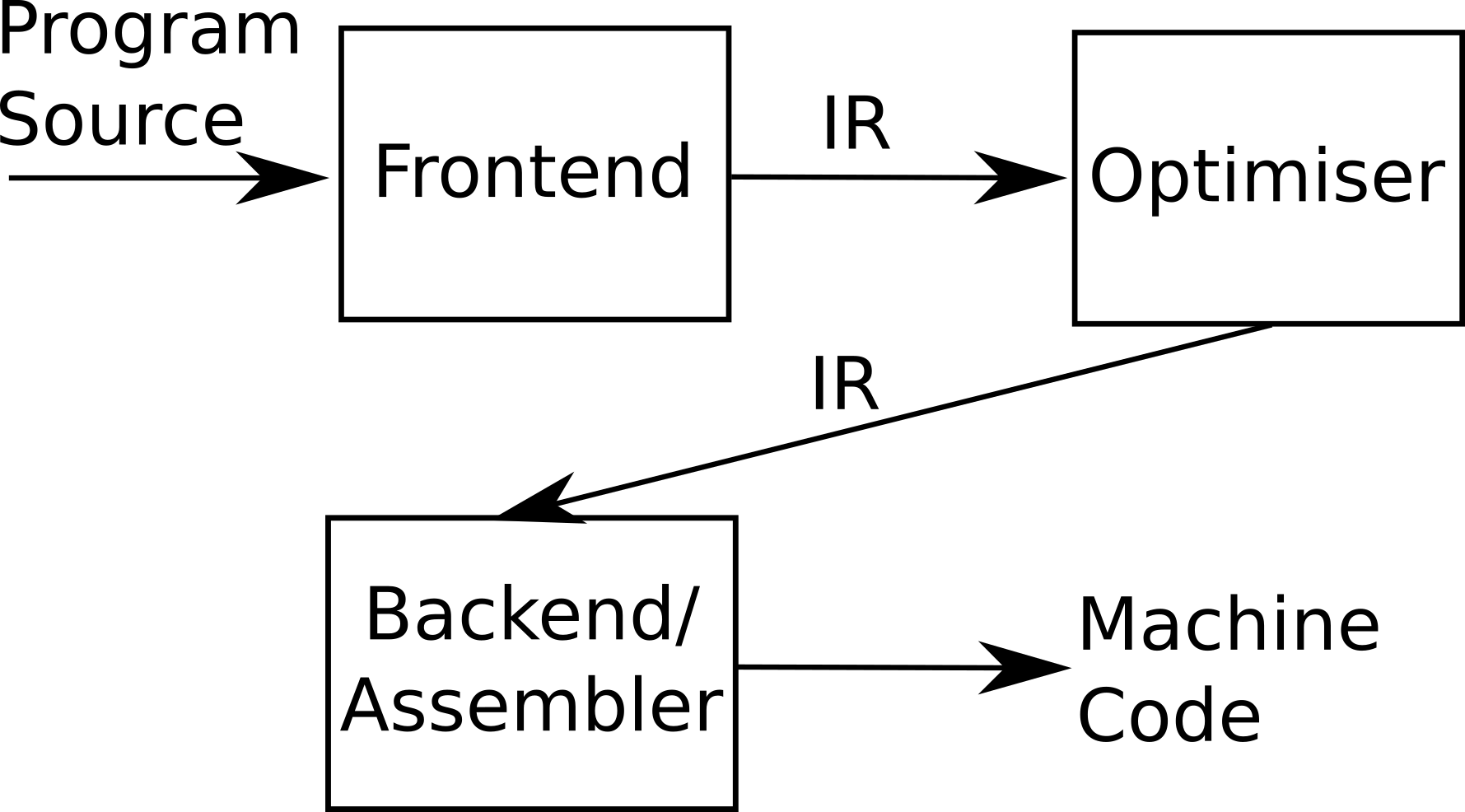
In reality, these three stages are not as well separated as I’ve made them out to be. Some optimisations will depend on features of the high-level language (some optimisations may be valid for C but not for Fortran), and some may depend on the specifics of the target architecture (some code paths may be faster on x86 than Arm or RISC-V), so there is significant overlap between the stages. But like I said, this view is good enough for the purpose of this blog post.
The multi-stage process turns out to be very useful for for language designers, since it allows the code optimisation and machine code generation stages (which are difficult and time consuming to write) to be re-used between projects. This cuts down the engineering effort required to implement a new programming language - instead of writing a whole new compiler, you can instead write a language frontend and then plug it into a mature framework like LLVM and boom! New language. And if you implement some clever optimisation in the middle-end, it can work just as well for C as it does for Fortran (modulo aforementioned differences in language semantics). This is nice for niche languages like Fortran, as it means we can piggyback off of the engineering efforts motivated by more popular languages like C.
As I said before, this is a drastically oversimplified view of compiler development, a field to which people dedicate their entire careers, but hopefully it’s enough background information to start really digging into how OpenMP constructs are actually implemented.
Compiling an OpenMP program
So where does OpenMP fit in this picture? Even though OpenMP #pragmas look like preprocessor directives (e.g.
macros and #includes), they’re not expanded by the preprocessor because their logic relies on having an abstract
representation of the program’s structure and control flow. Recall that the C preprocessor is essentially a fancy
text-substitution program 2: the preprocessor directive #define foo 10 is handled by finding all
instances of the string foo and replacing it with the string 10, for example. The preprocessor has no idea what
foo or 10 actually mean - that’s the parser + lexical analyser’s job. Given its limitations, the C preprocessor
is definitely not sophisticated enough to generate semantically correct parallel code, so expanding OpenMP directives
must happen later in the compilation pipeline.
In order to see what the OpenMP’d code looks like, we’ll need to inspect our code’s intermediate representation, after it’s been parsed but before it gets translated into either assembly or machine code.
GCC’s intermediate representation
Up to this point, I’ve used GCC for all my examples in this post because it’s kind of the de-facto standard C compiler in my field (scientific computing). But just because it’s the most widespread free compiler in my field doesn’t necessarily mean it’s the best or easiest to think about. GCC is an excellent compiler from a user perspective (it’s that rare piece of software where things mostly “just work”) and has quite competitive performance compared to the proprietary ones, but its internals are sparsely documented at best.
GCC includes
options for so-called debugging dumps at different compilation stages, including the intermediate
representation after all transformations and optimisations have been applied. We’ll be using the flag
-fdump-tree-optimized, which prints the IR, a language called GIMPLE - a
“human-readable”, tree-based form which sorta looks like C if you squint at it.
Even the human-readable GIMPLE is still pretty gnarly
(and not very well documented online, this was the best I could
find) but it’s the best we’re going
to get from GCC. There’s not a lot of documentation on GIMPLE, so trying to parse out what’s going on as
an outsider is somewhat reminiscent of reading tea leaves, but I’ve done my best in
this post.
With that out of the way, let’s look at some concrete examples.
Hello world, GCC edition
Let’s start our investigation into IR by looking at the IR of a simple, serial C program to wrap our head around what the compiler is doing. We’ll use a program which prints “hello world” in a somewhat overly-complicated fashion:
#include<stdio.h>
void say_hello(){
printf("Hello, world!\n");
}
int main(){
say_hello();
return(0);
}
Let’s compile the code with GCC, dumping the IR:
$ gcc -fdump-tree-optimized hello_serial.c
If you run this command yourself, you’ll find that GCC produces two files: the executable (a.out,
since we didn’t set an output name) and a file with a name like hello_serial.c.235t.optimized (the
exact number represents will differ between GCC versions and flags). This last
file contains
the “optimized” IR, which is close to the “actual code” which is executed by the computer when we run
the binary and is the file we’ll be focusing on in this section.
The IR of this program is short enough and simple enough that I can copy and paste it in its entirety
here and go through it line by line to explain what it all does. First, the IR:
;; Function say_hello (say_hello, funcdef_no=0, decl_uid=2331, cgraph_uid=1, symbol_order=0)
say_hello ()
{
<bb 2> :
__builtin_puts (&"Hello, world!"[0]);
return;
}
;; Function main (main, funcdef_no=1, decl_uid=2333, cgraph_uid=2, symbol_order=1)
main ()
{
int D.2336;
int _3;
<bb 2> :
say_hello ();
_3 = 0;
<bb 3> :
<L0>:
return _3;
}
Right away, we can see that our program contains two functions, say_hello and main, which is
reassuring. Each function has an associated header, which contains a bunch of information and
identifiers which are mostly useful in GCC’s optimisation passes, as well as when running the program
under a profiler or debugger. They’re not really relevant to this post, but I spent the time to look
up what they do so I’m going to give an explanation anyway:
funcdef_no- function ID number for debugging and profilingdecl_uid- this is a unique number chosen so that every declaration in this compilation unit (including#includes) can be uniquely identified within this unit. It’s basically there to allow you to use static variables with the same name in different compilation units, since their name will be mangled differently in the resulting binary and will not conflict.cgraph_uid- used when constructing a global call-graph, which comes into play with global optimisations like function inlining.symbol_order- I’m less sure about this one, but I think it’s here to keep track of the order in which the functions appear in the source code. Some optimisations re-order functions throughout the AST and object file, but sometimes you don’t want this (e.g. for extremely fiddly old code that implicitly relies on stuff appearing in a specific order), sosymbol_orderkeeps track of this.
After that header, we get a declaration of the function name, followed by its actual contents. In our
“Hello, world” case it’s pretty straightfoward: we get a declaration of a basic block 3 <bb 2>,
followed by a call to __builtin_puts which writes our string to stdout (we’re not using any format
specifiers, so there’s no need to use the full printf). __builtin_puts takes an address, so we feed
it the address of the first element of the string “Hello, world!”.
The main function is functionally the same, except it declares a dummy variable _3 to hold our
return value (0) and calls say_hello before returning.
Sick! That’s a program alright! This is a somewhat trivial example, but it contains enough information that we’ll be able to make sense of the equivalent program in OpenMP.
And now with threads!
Let’s return to our OpenMP “Hello, World!” example and inspect its intermediate representation in GCC. First,
the C source code (call it hello_omp.c) is:
#include<stdio.h>
#include<omp.h>
int main(){
printf("This is a serial region of code.\n");
#pragma omp parallel
{
printf("Entering the parallel region...\n");
int thread_num = omp_get_thread_num();
int num_threads = omp_get_num_threads();
printf("Hello from thread %d of %d!\n", thread_num, num_threads);
}
return(0);
}
Running this code with four threads should produce output similar to:
$ ./hello_omp
This is a serial region of code.
Entering the parallel region...
Hello from thread 0 of 4!
Entering the parallel region...
Hello from thread 1 of 4!
Entering the parallel region...
Hello from thread 2 of 4!
Entering the parallel region...
Hello from thread 3 of 4!
So far, so good. As we saw last time, this code compiles to two functions: main()
and main._omp_fn.0 (). The latter of these functions contains our outlined code, including the calls
to the OpenMP runtime functions, as well as the actual printing to the terminal, so this is the section
of code we want to focus our attention on.
Now if you compile this with GCC using the -fdump-tree-optimized flag, you should see the same pair of
files as before, but with filenames containing hello_omp instead. The contents look pretty familiar:
;; Function main (main, funcdef_no=0, decl_uid=2629, cgraph_uid=0, symbol_order=0)
main ()
{
int num_threads;
int thread_num;
int D.2634;
int _4;
<bb 2> :
__builtin_puts (&"This is a serial region of code."[0]);
__builtin_GOMP_parallel (main._omp_fn.0, 0B, 0, 0);
_4 = 0;
<bb 3> :
<L0>:
return _4;
}
;; Function main._omp_fn.0 (main._omp_fn.0, funcdef_no=1, decl_uid=2636, cgraph_uid=1, symbol_order=1)
main._omp_fn.0 (void * .omp_data_i)
{
int num_threads;
int thread_num;
<bb 2> :
printf ("Entering the parallel region...\n");
thread_num_4 = omp_get_thread_num ();
num_threads_6 = omp_get_num_threads ();
printf ("Hello from thread %d of %d!\n", thread_num_4, num_threads_6);
return;
}
As before, we have a main function which calls puts to tell use we’re in a serial region (so that’s
working properly) and then calls out to __builtin_GOMP_parallel, which is a compiler alias for
GOMP_parallel 4. This is the interesting part. We know
from poking around with GDB that the handler function GOMP_parallel takes as arguments a function
pointer to the contents of the parallel region (main._omp_fn.0, whose name is derived from the parent
region of code), a pointer to a struct with data (NULL
in this case because we don’t have any data clauses), the number of threads and some flags (which are
also zero in this case).
The only part of this which isn’t clear to me is why the number of threads
passed to main._omp_fn.0 is set to zero in the IR, while GDB shows it is set to 4 at runtime. After
reading this
page, it looks like this
is because at this stage of compilation GOMP_Parallel doesn’t need to define a special variable for
the number of threads, unless the user has requested a specific number of threads via the num_threads
clause. We can see this by adding num_threads(2) to the parallel clause in the example C code above,
it will produce exactly the same GIMPLE as before, but with the call to GOMP_parallel changed to:
__builtin_GOMP_parallel (main._omp_fn.0, 0B, 2, 0);
Notice that __builtin_GOMP_parallel now has a 2
for the value of NUM_THREADS. This value doesn’t appear anywhere in the GIMPLE IR, but I suspect it
will be used later when the builtins are resolved into the real OpenMP runtime functions to figure out
how many threads to spin up in this region (since #omp parallel num_threads(...) clauses take
precedence over the OMP_NUM_THREADS environment variable).
Finally, it’s interesting to note that the __builtins don’t seem to get resolved anywhere in the
middle-end - they’re left as essentially placeholders right up until the assembler (as near as I can
tell). I suspect this is because the optimal implementation of parallel algorithms change depend on the
characteristics of the target architecture (e.g. some CPUs might have really fast atomic operations),
so in general you’d want do as few translations as possible and let the back-end figure it out.
Fortunately the assembly for our hello world example is fairly short and uncomplicated, so we can check
this for ourselves by compiling the code with:
gcc -S -Os -fopenmp hello_omp.c -o hello_omp.s
The -S flag emits assembly (in the file hello_omp.s) and -Os optimises for smaller binaries, which I find
sometimes makes the assembly easier to follow. I won’t post the whole thing here, but we can take a peek
at main and the outlined function to get an idea of what’s going on:
main._omp_fn.0:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movl $.LC0, %edi
call puts
call omp_get_thread_num
movl %eax, %ebp
call omp_get_num_threads
movl %ebp, %esi
movl $.LC1, %edi
popq %rbp
.cfi_def_cfa_offset 8
movl %eax, %edx
xorl %eax, %eax
jmp printf
.cfi_endproc
...
main:
.LFB0:
.cfi_startproc
pushq %rax
.cfi_def_cfa_offset 16
movl $.LC2, %edi
call puts
xorl %edx, %edx
xorl %ecx, %ecx
xorl %esi, %esi
movl $main._omp_fn.0, %edi
call GOMP_parallel
xorl %eax, %eax
popq %rdx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
(I’ve deliberately omitted a whole bunch of definitions, but the most important thing to know is that
LC[0-2] are the strings our program prints out). We can see that the main function first prints LC2
(“This is a serial region of code.”) through puts, then zeroes out three registers used to pass
arguments to function calls (by xor-ing whatever was in the register with itself), loads up the
address of our outlined function into a third (%edi) and then calls GOMP_parallel (before packing up
once it’s returned). This all makes sense, and I think it nicely confirms my intuition as to how OpenMP
transforms simple parallel regions into executable code.
Loops
Of course, we can’t just leave things at a “hello world” and call it a day - that barely even counts as a parallel program. Let’s look at some loops.
Pretty much every course on OpenMP starts with parallel for/do loops, since this is the easiest parallel construct to explain in terms of imperative programming languages like C or Fortran. While I can quibble with this from a pedagogical perspective 5, I’ll using parallel loops here as it leads to significantly shorter IR and assembly than task parallelism. This will also give us the opportunity to look at how data sharing clauses are handled, at least in a basic sense.
However, before we look at any parallel code, it’s probably a good idea to look at the IR and assembly for a basic for-loop so we have a point of comparison to refer back to later on. Here’s the C code:
#include<stdio.h>
int main(){
int x = 5;
for(int ii = 0; ii < 10; ii++)
{
printf("ii = %d, x = %d\n", ii, x);
}
return(0);
}
If we compile this with the right flags, we get the following GIMPLE IR:
;; Function main (main, funcdef_no=0, decl_uid=2358, cgraph_uid=0, symbol_order=0)
main ()
{
int ii;
int x;
int D.2366;
int _8;
<bb 2> :
x_3 = 5;
ii_4 = 0;
goto <bb 4>; [INV]
<bb 3> :
printf ("ii = %d, x = %d\n", ii_1, x_3);
ii_7 = ii_1 + 1;
<bb 4> :
# ii_1 = PHI <ii_4(2), ii_7(3)>
if (ii_1 <= 9)
goto <bb 3>; [INV]
else
goto <bb 5>; [INV]
<bb 5> :
_8 = 0;
<bb 6> :
<L3>:
return _8;
}
Hopefully the syntax of this IR should be somewhat familiar now, so I’ll only do a brief run-through
of the logic and program flow. First, we declare and initialise the “common” variable x (which doesn’t
do anything useful here, but will play a bigger part when we move to OpenMP) and the loop counter ii
and then jump (goto) basic-block 4, which is our loop’s execution condition (ii < 10). Worth noting
is the GIMPLE PHI node, which occurs whenever a variable can take different values depending on where
we are in the program’s control flow and essentially “merges” those values into a single expression. In
this case, ii can either have its initial value (0) if we’re coming from basic-block 2 or the value
of the loop index if we’re coming from basic-block 3. This is a very artificial construct which is only
necessary to maintain the single static assignment
(SSA) format of the IR, and makes it
easier for the compiler to reason about programming semantics. Finally, if this conditional is true,
then we jump to basic-block 3 and execute the loop’s body: print a message to the screen and increment
the loop counter, before falling through to the conditional again. Otherwise we skip to basic-block 5
and exit the program.
If you’ve ever written any assembly, you’ll recognise that this is almost identical to how you write a for-loop in (x86) assembly. Indeed, the semantics of GIMPLE (particularly the requirement which forces expressions to have at most two operands) mean that, barring any OpenMP funny business, the IR will almost always look like the assembly.
For completeness sake, let’s look at the generated assembly:
.file "for.c"
.text
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "ii = %d, x = %d\n"
.section .text.startup,"ax",@progbits
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
xorl %ebx, %ebx
.L2:
movl %ebx, %esi
movl $5, %edx
movl $.LC0, %edi
xorl %eax, %eax
call printf
incl %ebx
cmpl $10, %ebx
jne .L2
xorl %eax, %eax
popq %rbx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 8.3.1 20191121 (Red Hat 8.3.1-5)"
.section .note.GNU-stack,"",@progbits
I won’t go over the program logic, since it would be identical to the one for the IR. Again, the assembly will become slightly more complex as we introduce OpenMP, but it’s useful to have a baseline to compare against.
OpenMP parallel for
Static scheduling
Alright, so let’s move on to a parallel for-loop. In this section I’m going to go over the implementation of a super basic parallel for-loop with the basic, default static scheduling (we’ll look at other scheduling policies in the next post).
Here’s the source code for the first parallel loop:
#include<stdio.h>
#include<omp.h>
int main(){
int x = 0;
#pragma omp parallel for shared(x)
for(int ii = 0; ii < 10; ii++)
{
int thread_num = omp_get_thread_num();
#pragma omp critical
{
x++;
printf("Thread %d got ii = %d, x = %d\n", thread_num, ii, x);
}
}
return(0);
}
The C source code of looks very similar to the
serial version, which is of course one of OpenMP’s great strengths. The only real differences are
the parallel construct (pragma omp parallel...), which includes a data-sharing directive to
demonstrate how threads share (or don’t share) variables, as well as a critical section containing some
additional arithmetic on our shared variable x, which isn’t present in the serial code but I’ve added
it here because it better demonstrates the semantics of shared variables in OpenMP and it’s interesting
to look at how it’s implemented. This critical section also guards the print statement (ensuring the
output doesn’t end up all garbled).
Speaking of output, if you run this code with four threads, you should see output which looks something like:
Thread 0 got ii = 0, x = 1
Thread 0 got ii = 1, x = 2
Thread 2 got ii = 4, x = 3
Thread 2 got ii = 5, x = 4
Thread 1 got ii = 2, x = 5
Thread 1 got ii = 3, x = 6
Thread 3 got ii = 6, x = 7
Thread 4 got ii = 8, x = 8
Thread 3 got ii = 7, x = 9
Thread 4 got ii = 9, x = 10
Pretty straightforward, and demonstrates the default static
scheduling
of loop iterations to threads,
where each thread gets a contiguous block, or chunk, of iterations. By default, the run-time tries to
give each thread a chunk size of floor(num_iter/num_threads), with any leftovers (in the
case where the number of threads isn’t a neat factor of the number of iterations) going being spread as
evenly as possible between threads. We’ll talk some more about scheduling in a later post, but I wanted
to point it out here while I had the chance (this is foreshadowing). And finally, we can see that the
value of x is shared between all threads (even though guarded by a critical section) as it very neatly
follows the loop iterations. In this case it is exactly equal to the value of the loop variable ii,
but this is just a fluke of the scheduling choice made by the run-time - there’s nothing in the standard
which requires a particular thread-ordering, so something like the following would also be perfectly
valid output:
Thread 0 got ii = 9, x = 1
Thread 0 got ii = 8, x = 2
Thread 2 got ii = 7, x = 3
Thread 2 got ii = 6, x = 4
Thread 1 got ii = 5, x = 5
Thread 1 got ii = 4, x = 6
Thread 3 got ii = 3, x = 7
Thread 4 got ii = 2, x = 8
Thread 3 got ii = 1, x = 9
Thread 4 got ii = 0, x = 10
It turns out that GCC usually monotonically assigns work for static scheduling, so “each thread executes the chunks that it is assigned in increasing logical iteration order” (although the order in which iterations assigned to different threads are executed is still unspecified). OpenMP version 5.0 introduced some changes to the semantics of how chunks are assigned and executed, but again, that’s a topic for a later post.
Right, so far, so good. Let’s look at the IR.
I’m not going to post the whole thing here because it’s really long with a lot of temporary variables.
Instead, I’m just going to post the important bits and elide all the boring bits (signified by a
... elipsis); hopefully it should still convey the important aspects of the implementation. Here’s the
code:
;; Function main (main, funcdef_no=0, decl_uid=2656, cgraph_uid=1, symbol_order=0)
main ()
{
...
struct .omp_data_s.0 .omp_data_o.1;
...
<bb 2> :
x_1 = 0;
.omp_data_o.1.x = x_1;
__builtin_GOMP_parallel (main._omp_fn.0, &.omp_data_o.1, 0, 0);
x_5 = .omp_data_o.1.x;
.omp_data_o.1 ={v} {CLOBBER};
_7 = 0;
<bb 3> :
<L0>:
return _7;
}
;; Function main._omp_fn.0 (main._omp_fn.0, funcdef_no=1, decl_uid=2664, cgraph_uid=2, symbol_order=1)
main._omp_fn.0 (struct .omp_data_s.0 & restrict .omp_data_i)
{
int x [value-expr: .omp_data_i->x];
...
<bb 2> :
_6 = __builtin_omp_get_num_threads ();
_7 = __builtin_omp_get_thread_num ();
q.2_8 = 10 / _6;
tt.3_9 = 10 % _6;
if (_7 < tt.3_9)
goto <bb 7>; [25.00%]
else
goto <bb 3>; [75.00%]
<bb 3> :
# q.2_1 = PHI <q.2_11(7), q.2_8(2)>
# tt.3_2 = PHI <tt.3_10(7), tt.3_9(2)>
_12 = q.2_1 * _7;
_13 = _12 + tt.3_2;
_14 = _13 + q.2_1;
if (_13 >= _14)
goto <bb 6>; [INV]
else
goto <bb 4>; [INV]
<bb 4> :
ii_16 = _13;
<bb 5> :
# ii_3 = PHI <ii_27(5), ii_16(4)>
thread_num_18 = omp_get_thread_num ();
__builtin_GOMP_critical_start ();
_21 = .omp_data_i_20(D)->x;
_22 = _21 + 1;
.omp_data_i_20(D)->x = _22;
_24 = .omp_data_i_20(D)->x;
printf ("Thread %d got ii = %d, x = %d\n", thread_num_18, ii_3, _24);
__builtin_GOMP_critical_end ();
ii_27 = ii_3 + 1;
if (ii_27 < _14)
goto <bb 5>; [INV]
else
goto <bb 6>; [INV]
<bb 6> :
return;
<bb 7> :
tt.3_10 = 0;
q.2_11 = q.2_8 + 1;
goto <bb 3>; [100.00%]
}
There’s a lot to unpack here, so strap yourselves in. Let’s start with the main function. The first
thing to note is that the compiler has defined a struct
called .omp_data_o.1, which is a completely synthetic variable - it exists entirely as a compiler aid
to manage OpenMP’s data sharing environment. It only has one member in this case, x, which is
initialised to 0 at the start of <bb 2>. The main function then immediately calls out to
GOMP_parallel, using the outlined parallel region and the data struct as arguments, before extracting
the value of x from .omp_data_o.1 into a new local variable x_5. The line .omp_data_o.1 ={v}
{CLOBBER}; doesn’t have any user-observable characteristics and is another convenience for the
compiler; it indicates that the data struct no longer has a definite value and has gone out of scope
(the internal OpenMP variables are only semantically meaningful inside parallel regions, after all).
As we might expect from our previous examples, the main point of this main function is to set up the
parallel execution environment and launch the parallel run-time. If we want to see the actual parallel
logic then we need to start poking around in the outlined function, main._omp_fn.0.
First up, we extract the value of x from the data sharing struct. Then, the outlined function
calculates the quotient and remainder of Num. iterations and Num. threads
which we’ll use to divide the
loop iterations between threads. The execution flow then branches based on the ID of the current thread:
threads 0 to 10 % Num. threads (the “leftover” iterations once we’ve evenly distributed then between
threads) jump to <bb 7>, which increases it’s number of assigned iterations (q.2_11) by 1. This is
how static scheduling is handled by the compiler; we’ll have a look at dynamic scheduled loops
later.
An interesting feature of conditionals in the IR are the annotations in square brackets: the compiler provides an estimate of the probability of each branch being taken, which is used in optimisations such as re-arranging the ordering of machine-code instructions to take better advantage of pipelining and branch-prediction. Since we haven’t done anything special, GCC will use some heuristics to guess these probabilities, but there are techniques like profile-guided optimisations which provide a better guess. Obviously it’s not going to have a huge impact on the performance of our toy code, but it’s still pretty cool and worth knowing about.
Next, the code at <bb 3> handles the case where we have more threads than loop iterations, in which case
some threads will have no work to do. The logic is hard to follow in GIMPLE, so let’s look at a concrete
example where there are more threads than iterations: set Nthreads = 11 and the number of loop
iterations to 10. Back in <bb 2>, we calculated the remainder and quotient of the loop bound with
Nthreads; here that gives us q = 10 / 11 = 0 (this is an integer division operation, so it truncates
fractional results) and tt = 10 % 11 = 11. This means that once we run through <bb 2> and <bb 7>
all threads with TID <= 10 will get a single iteration, corresponding to q.2_11 = 1, while the
thread with TID = 11 will get q.2_8 = 10/11 = 0. Running through <bb 3>, we can now evaluate the
statements one-by-one for each case. For the threads with TID <= 10, we have:
_12 = q.2_1 * _7; // 1 * omp_get_thread_num()
_13 = _12 + tt.3_2; // 1 * omp_get_thread_num() + 0
_14 = _13 + q.2_1; // 1 * omp_get_thread_num() + 0 + 1
_13 is clearly less than _14, so these threads go through to the main body of the function
(<bb 4>). For thread TID = 11:
_12 = q.2_1 * _7; // 0 * omp_get_thread_num()
_13 = _12 + tt.3_2; // 0 * omp_get_thread_num() + 11
_14 = _13 + q.2_1; // 0 * omp_get_thread_num() + 11 + 0
In this case _13 == 14, so this thread immediately exits the parallel region, as we expected. This
logic is somewhat convoluted, but is necessary to deal with edge-cases like weird chunk sizes
(e.g. if we were to manually specify that threads should get 4 iterations each by doing #pragma omp
parallel for schedule(static, 4)).
Cool, now let’s move on to the meat of the parallel region.
<bb 5> does the actual observable work by “entering” a critical region (logically, it’s like obtaining
a mutex) and incrementing x via the data-sharing struct .omp_data_i_20. This step takes multiple
instructions to carry out (and looks pretty convoluted) in order to satisfy the requirements of the SSA
form. Finally, we print our message (including the OpenMP thread ID), check the loop bound condition and
then either repeat or exit the function. Since we’ve already apportioned loop iterations to threads,
the loop boundary condition is pretty simple in form. This is the key characteristic of static
scheduling: it’s dead simple and has almost no run-time overhead, but that simplicity comes at the cost
of inflexibility. Each thread gets a pre-determined number of iterations and the iterations are
distributed according to a fixed pattern (the thread 0 gets the first n iterations, thread
1 gets the next n and so on) which works fine if the chunks all take the same amount of time to
execute, but any imbalance in the chunk size will cause a corresponding workload imbalance across the
threads - very bad for performance.
This is where dynamic scheduling comes in handy, so let’s take a quick look at it now.
Dynamic scheduling
The C code of this example looks almost identical to the last one. In fact, the only difference is that
we add schedule(dynamic) to the parallel directive, which becomes #pragma omp parallel for
schedule(dynamic):
#include<stdio.h>
#include<omp.h>
int main(){
int x = 0;
#pragma omp parallel for shared(x) schedule(dynamic)
for(int ii = 0; ii < 10; ii++)
{
int thread_num = omp_get_thread_num();
#pragma omp critical
{
x++;
printf("Thread %d got ii = %d, x = %d\n", thread_num, ii, x);
}
}
return(0);
}
That’s it! Fortunately, the IR is also not that much more complicated either. As before, I’ve elided a lot of the boilerplate, focusing on the parts which are important to understanding the underlying implementation:
;; Function main (main, funcdef_no=0, decl_uid=2656, cgraph_uid=1, symbol_order=0)
main ()
{
...
<bb 2> :
x_1 = 0;
.omp_data_o.1.x = x_1;
__builtin_GOMP_parallel_loop_nonmonotonic_dynamic (main._omp_fn.0, &.omp_data_o.1, 0, 0, 10, 1, 1, 0);
x_5 = .omp_data_o.1.x;
.omp_data_o.1 ={v} {CLOBBER};
_7 = 0;
<bb 3> :
<L0>:
return _7;
}
;; Function main._omp_fn.0 (main._omp_fn.0, funcdef_no=1, decl_uid=2664, cgraph_uid=2, symbol_order=1)
main._omp_fn.0 (struct .omp_data_s.0 & restrict .omp_data_i)
{
...
<bb 2> :
_7 = __builtin_GOMP_loop_nonmonotonic_dynamic_next (&.istart0.2, &.iend0.3);
if (_7 != 0)
goto <bb 3>; [INV]
else
goto <bb 6>; [INV]
<bb 3> :
.istart0.4_8 = .istart0.2;
ii_9 = (int) .istart0.4_8;
.iend0.5_10 = .iend0.3;
_11 = (int) .iend0.5_10;
<bb 4> :
# ii_1 = PHI <ii_22(4), ii_9(3)>
thread_num_13 = omp_get_thread_num ();
__builtin_GOMP_critical_start ();
_16 = .omp_data_i_15(D)->x;
_17 = _16 + 1;
.omp_data_i_15(D)->x = _17;
_19 = .omp_data_i_15(D)->x;
printf ("Thread %d got ii = %d, x = %d\n", thread_num_13, ii_1, _19);
__builtin_GOMP_critical_end ();
ii_22 = ii_1 + 1;
if (ii_22 < _11)
goto <bb 4>; [87.50%]
else
goto <bb 5>; [12.50%]
<bb 5> :
_24 = __builtin_GOMP_loop_nonmonotonic_dynamic_next (&.istart0.2, &.iend0.3);
if (_24 != 0)
goto <bb 3>; [INV]
else
goto <bb 6>; [INV]
<bb 6> :
__builtin_GOMP_loop_end_nowait ();
return;
}
The first difference which stands out is the call to the OpenMP parallel runtime. In this case, it is
__builtin_GOMP_parallel_loop_nonmonotonic_dynamic() (rather than the usual
__builtin_GOMP_parallel()), which indicates that the loop uses dynamic scheduling (obviously) and is
nonmonotonic, which is a “new” feature from OpenMP 4.5 (it’s old in absolute terms, but still new enough
that it wasn’t taught in my undergrad parallel programming course). The gist of nonmonotonic
scheduling (which looks like it’s the
default for dynamically scheduled loops but can be changed in the loop’s schedule clause)
is that it’s a way to signal to the compiler that the semantics
of a particular loop do not depend on the chunks executing in “ascending” order; i.e. threads are
allowed to execute iteration i-1 after iteration i if the runtime determines it to be more efficient.
This apparently reduces the overhead in dynamic scheduling and allows for the possibility of a thread
bailing out of the loop early (at least, according to this
talk). Unfortunately, the IR
gives us no clue as to how this is implemented since it’s encapsulated in calls out to OpenMP
runtime functions, so we’ll have to look into the libgomp source code in a future entry.
The other main difference between the code for dynamic vs static scheduling is how distributing
iterations/chunks between threads is handled. Remember, in static scheduling, the iteration space
is divided up between threads according to a simple-ish formula before the actual body of the
parallel loop is executed (hence the name static). Our dynamic loop does something different: it calls
out to the builtin function GOMP_loop_nonmonotonic_dynamic_next, first at the start of the parallel
region to get the indices in each thread’s first scheduled chunk, and then again whenever a thread
finishes its chunk to check if there’s any more work left to do. Logically, this is probably implemented
by some central work queue which the *_dynamic_next calls out to, but as before, the GIMPLE IR doesn’t
give us information on how it’s implemented. It does, however, give us an idea of what to look for and
the names of library functions which are worth checking out, so it’s a good starting point. The rest of
the code is then the same as in the static scheduling case.
Summing up
So what have we learned so far? We know that GCC generates parallel regions by outlining: it hoists the contents of a parallel region into an artificial function, which serves as the work function for the OpenMP threads. Our simple examples demonstrate that the outlining happens in the “middle-end” of the compiler, after the source code has been parsed and the IR generated. The IR itself only contains a placeholder call to the OpenMP runtime routines, since the true invocation of the run-time code happens as the final machine code (or assembly) is generated. We also know that the choice of scheduling policy can have a pretty big effect on the generated code (if not the program’s observables) but again, most of the interesting stuff takes place in runtime library functions.
This is a pretty good high-level overview, but it’s still missing a lot of information. Our simple
examples barely rise to the level of toy programs and it would be
cool to see how all of this is implemented for a realistic program. I had originally planned to include
a section doing exactly this, but it turned out to be much longer than I expected - long enough that it
probably deserves its own post. And besides, this is already a huge blog post so probably doesn’t need
even more content. We’ll also need to start looking at the actual libgomp source code to see what the
runtime functions actually do regarding things like workload scheduling, which will have to be another
post further down the line.
Thanks for sticking with me to the end of this very long exploration of OpenMP and compilers, and I hope you’ll join me again next time for a look at how this all comes together in real code for numerical integration.
EDIT 19/06/2021: References
By request, here are some resource I found useful while writing this post, as well as a seminar from after I wrote this covering similar(-ish) material.
OpenMP implementation references
These references focus on the implementation details of OpenMP in GCC and LLVM, although they lean more heavily towards LLVM because that community seems to have a stronger norm around producing public-facing documentation. They only deal with traditional CPU parallelism, since I plan to deal with device (GPU) offloading in a later post. These resources served as a good starting point, but there wasn’t very much information on GCC’s OpenMP implementation, so most of my research for this post involved reading the source-code, as well as reverse-engineering IR and assembly.
- LLVM OpenMP implementation reference: this document details how OpenMP constructs are implemented in LLVM (e.g. Clang and Flang) in fairly close detail. I found it to be a very useful starting point for this post, since the high-level details will necessarily be very similar across compilers.
- GCC libgomp ABI reference: the GCC equivalent of the first document in this section. It’s considerably less detailed than the LLVM equivalent, but was an okay reference for the GCC-ism.
- How do OpenMP Compilers Work? Parts 1 and 2, Michael Klemm: these two blog posts (written by the Chief Executive Officer of the OpenMP Architecture Review Board) cover similar material to this post, but without diving into intermediate representation (the code is mostly C and C-like pseudocode). Still a very interesting read.
- A Compiler’s View of OpenMP, Johannes Doerfert: this webinar discusses how OpenMP constructs are implemented in LLVM, with a particular focus on its interactions with compiler optimisations, as well as device offloading. This webinar was published after I wrote this post (and has a slightly different focus), but I’m including it here because it’s a very useful resource.
Compiler resources
These resources focus on the engineering of compilers in general, and GCC in particular. This list mainly focuses on specific compiler internals, but I have included a couple of general compiler books for good measure.
- Compilers: Principles, Techniques, and Tools, Aho, Lam, Sethi and Ullman: more commonly referred to as The Dragon Book, this is a classic in compiler design and engineering. It’s fairly old (even the second edition is from 2006) and I’ve heard that much of the material is outdated, but it’s an entertaining read and introduces some foundational concepts that I wasn’t really familiar with before I started researching this post last year (disclaimer: I haven’t finished reading this yet).
- Building an Optimizing Compiler, Robert Morgan: this is a slightly more advanced book on compiler design than The Dragon Book with descriptions of more modern algorithms (disclaimer: I also haven’t finished this yet. I have too many books in my “to read” queue).
- GCC Internals Reference Manual: self-explanatory. Very broad and useful, but I found it hard to follow until I’d read the other resources on this list and familiarised myself with the concepts (which is fair, the manual is probably meant for compiler developers who can probably be expected to have some degree of expertise already).
- GCC for New Contributors, David Malcolm: list of resources curated by a GCC developer at Red Hat. I used this as a starting point for learning about GCC’s middle-end and intermediate representation. GCC Python Plugin documentation, David Malcolm: this is the documentation for a python tool for writing GCC plugins. By necessity, it talks a lot about GCC’s internals, since it needs to hook into various stages of compilation. Of particular use was the Overview of GCC’s Internals.
- GCC GIMPLE Reference: self-explanatory. Kind of sparse on details, but was useful when combined with the other resources on this list.
- Writing a GCC back end, Krister Walfridsson: this series of blog posts details the process of developing a new backend for GCC, and is an excellent “worked example” of how a lot of this stuff works.
-
There’s one source-to-source compiler which is actually very relevant to this ongoing series called ompi, which “takes C code with OpenMP directives and transforms it into multithreaded C code ready to be compiled by the native compiler of a system.”. That is to say, it transforms C + OpenMP into a form which preserves the logic of parallelism, but is more explicit in how it uses OS-threads. I may take a look at it in a future post, if I get around to it. ↩
-
Like basically everything in this post, the reality is a lot more complicated. Modern preprocessors (as opposed to the abstract ideal established in the ISO standard) actually operate on tokens not text, per se, and there’s some subtleties when it comes to importing system headers like
stdio.h. If you’re like me and have a strange sense of fun, it’s worth readingman CPP(1)to get the full picture. ↩ -
bb= basic block, an atomic series of instructions which are chained together into the call graph ↩ -
This is defined in the appropriately named
omp-builtins.def. ↩ -
For the curious, I think it’s better to start teaching parallel programming by breaking the workload into atomic (indivisible) tasks to encourage students to think in terms of decomposition (and especially over-decomposition), and then introducing parallel loops as a way to retrofit that mental model onto previously serial codes. I think task parallelism (plus asynchronous execution) is more intuitive to reason about, since this is how people tend to distribute work among small teams in the real world and it also maps very neatly to domain-decomposition problems, which are extremely common. It’s also a pattern which probably scales better to massively parallel architectures, as typified by post-MPI frameworks like Charm++. These are kind of half-baked thoughts though, and I may or may not write a full post on this topic later. ↩